“Big data” has been in the news a lot lately. Where does all the information that gets funnelled through our social media feeds actually get stored? And who is ever going to look at this stuff anyway?
These are important questions in light of the fact that we are living in a world moving at warp speed where content is created, absorbed, and then deleted from our virtual screens within seconds. Facebook news feeds and LinkedIn group discussion content are refreshed at the blink of an eye. Photos on Instagram and Pinterest are replaced by cooler, catchier, and sexier content each time we check our profiles. Content is fleeting and temporary at best.
Knowledge is as good as our neural networks are in absorbing the flashes of news that beam at us from every available digital nook and cranny. Our human brain capacity to curate, process, and store all of this information is limited by our finite levels of will power. In turn, our will power can be easily depleted by exhaustion, stress, and boredom. Our brains, to keep the energy efficient mechanism of automaticity in our thoughts and behaviors, will choose to “switch” off and rely on past memories to run our lives.
But there is a gold mine of data swimming in the ocean of the “internet of things” often referred to as “big data”, data mining, database knowledge discovery, data predictive analytics, or data science. And thank goodness for systems like Hadoop, which leverages MySQL as a structured query language to select and analyze data files based on specific conditions. Once big data is queried and refined, it can be analyzed with a number of tools such as R and Python. Instead on relying on the human brain, which needs rest, variety, and diversions to keep it interested, we can leverage machines and complex algorithms to churn through massive databases on our behalf.
Social media database meccas such as Google, Facebook, LinkedIn, Yahoo, and Twitter all leverage their big data warehouses to help predict behaviors and build better tools for people to use in order to make their lives better. Big data also promises huge potential benefits in genomics, clinical trial management, disease management, and patient medical intervention adherence protocols.
Behavior Prediction and Self Quantification
From a pure psychology standpoint, big data has begun to weigh in on areas such as wellness, mental health, depression, substance abuse, behavioral health, behavior change, and workplace well-being and effectiveness. With the rampant use of wearables and health trackers such as Fitbit, Jawbone, Oura, and heart rate variability monitor Inner Balance, a new science revolving around the “quantified self” is emerging. The brilliance will be in linking the personal health data accumulated in these trackers to reveal population-based dynamic patterns in behaviors with specific outcomes. Once we start to understand these patterns and trends, we can start studying how specific interventions can impact these connections.

What is fascinating about our current blockchain world with knowledge abounding within the vasculature of the internet ecosystem, is it has allowed data mining to occur with minimal cost and across multiple time zones, cultures, and geographies. New partnerships and virtual relationships have developed as a result of this high level of visibility and accessibility. Fold in machine learning and “smart” computers with built-in artificial intelligence algorithms, and you now have a technological environment that can read and predict individual behavior. We see this with home management systems like Nest and with chatbots like Amazon Echo and Google Home. With this, however, comes a huge responsibility of maintaining the security and privacy of individual information.
Big Data Analysis Systems
APIs
To simplify and declutter our lives, there has been increased emphasis on application programming interfaces, or APIs, to allow software applications to interconnect and “speak” to each other more readily. This is how capabilities can be consolidated and analytics dashboards can be centralized instead of being dispersed in multiple portals and platforms. To this end, we have seen a plethora of visual databases enter the market like Airtable, Fieldbook, Microsoft BI, Domo, Tableau, InsightSquared, Chartio, and Looker.
Web Scraping
Web scraping, an automated process where data can be extracted from backend websites to help populate centralized data warehouses or applications, has also been flooding the data market. Data scientists have utilized platforms such as CapturePoint, dexi.io, ReportMiner, Mozenda, and Monarch, just to name a few. Theory driven methods have been used to ascribe meaning to the key components of the scraped data and allow for “junk” information that is not useful to be discarded. This can be fashioned to mining for diamonds and then tossing out the debris which contains no value.
SVD and LDA
Large databases, often referred to as “digital footprints” (found in Facebook and Twitter), when analyzed to understand and predict relevant outcomes, can be excellent mining grounds for researchers and data scientists. They utilize procedures such as singular value decomposition (SVD) to conduct principal components analyses and latent dirichlet allocation (LDA) clustering procedures to help form dimensions with similar content. With LDA, heatmaps are used to show darker colors when a personality trait or characteristic is more correlated with an LDA cluster.
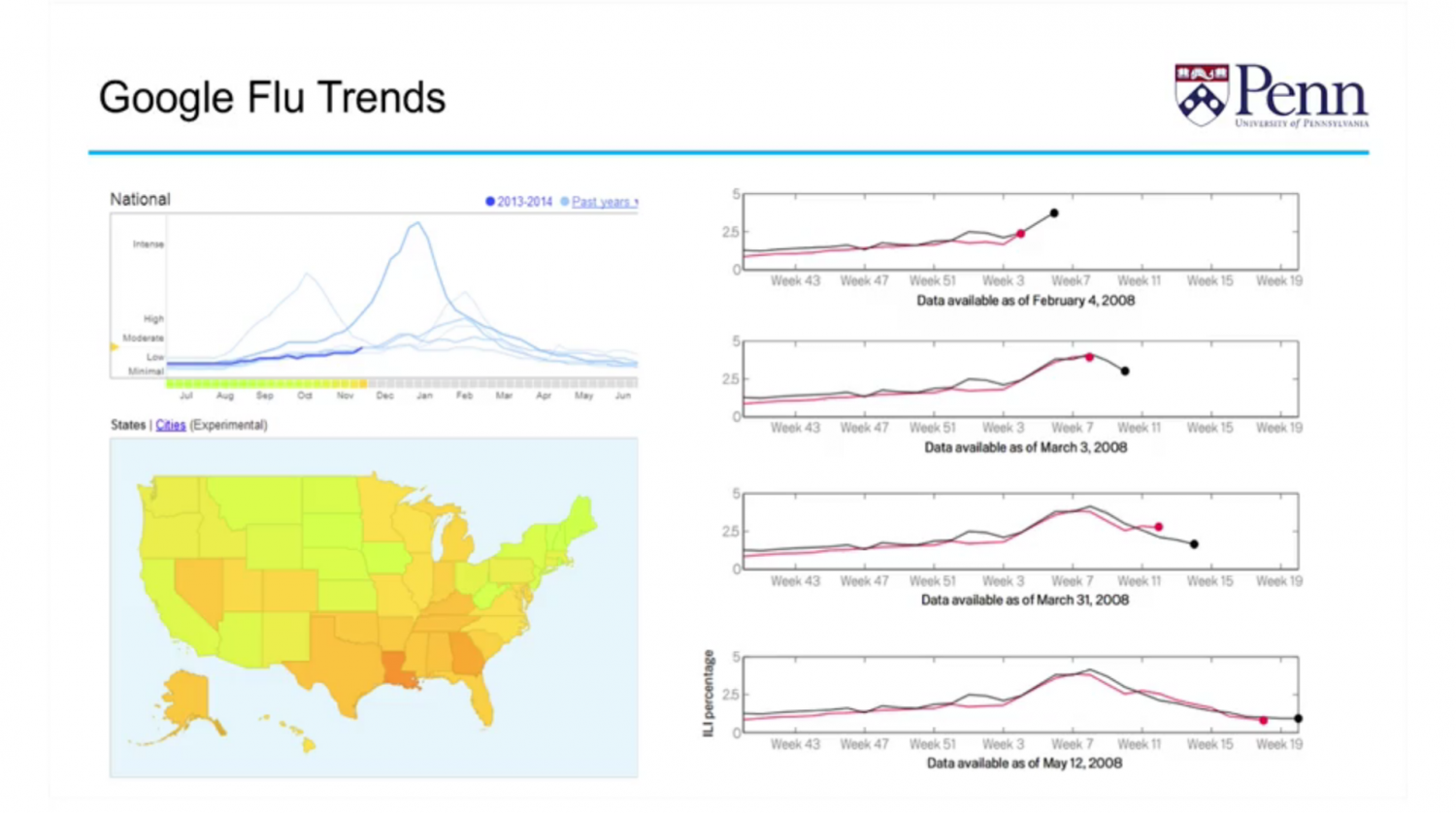
This methodology was demonstrated in 2009. Google measured the occurrence of search queries related to the flu and then deduced how the flu would spread through the United States. They created a map and a time series that showed how the flu developed across the country through the seasons. Google’s estimates were about two weeks ahead of the estimates from the leading medical authorities in the US about the incidents of flu tracked at around 98% accuracy. This became the proof of concept that the internet and data flows could predict people’s behaviors. Google realized that they no longer needed to check reports from the Centers for Disease Control and could now just observe data flows in order to capture the same information.
Differential Language Analysis and Regression Models
Other procedures known as “differential language analysis” help to reduce the large amount of text based information found on the internet into smaller relevant dimensions so they can be more effectively analyzed. Methods such as lasso (least absolute shrinkage and selection operator), k-fold cross-validation, and other regression models can help predict future outcomes. Unfortunately, these large database predictor models can derive erroneous conclusions when ecological and exception fallacies surface.
Linguistic Inquiry and Word Count
Researchers have also utilized “Linguistic Inquiry” and “Word Count” to analyze psychological themes by extracting regional and time dependent events and testing for negative emotional responses. They try to reduce errors by identifying people who follow relevant community networks tied to specific geographical areas of the event and then compare these to control groups who were more geographically dispersed.
Predictive Word Tags
Others have utilized Twitter and Stack Overflow to analyze and predict tags that users would apply to their posts. By studying the nature, recency, and frequency of past user behaviors, and leveraging the tenant that “past behavior will predict future behavior”, they are able to utilize random permutation models to understand and clarify predictions about links between processes and outcomes.
Data Decision Trees
Interesting approaches to organizing large datasets include structural equation model decision trees, which combine both data and theory-based approaches to testing hypotheses. Data scientists are able to test the accuracy of their data models by comparing variable importance, proximity, dissimilarity, and novelty metrics. There are also a series of machine learning and statistical learning theories that can be used to measure psychometric reliability of data sets as well as the level of correlation between multivariate data as is seen with the analysis of genetic information.
Population Studies Using Social Media
With all of these fantastic advancements in big data number crunching and analysis, you may be wondering what “data” we are actually speaking about. We are not talking about data from typical clinical studies which normally include a finite number of subjects ranging between 50 to 3000 patients. With social media, researchers now have access to billions of people through platforms like Facebook, Twitter and the like. This is a huge opportunity from a scaling and statistics standpoint. This global data warehouse comprised of billions of social media users is the kind of data researchers are now navigating.
When data scientists began to incorporate social media listening into their research, they noticed that people behaved in different ways when they were not being actively “observed”. That is to say, people will act more “freely” in their own environment and when left to their own devices. In addition, people only function within the spheres of “knowing what they know” and if asked a typical survey question, will respond in order to deliver a contrived notion of who they think they are or provide you with responses they think you would like to hear. Observing natural behaviors on social media is one of the “cleanest” ways to capture the meaning between the lines.
A great example of “Linguistic Inquiry” and “Word Count”, is a study that was conducted by Johannes Eichstaedt of the Positive Psychology Department at the University of Pennsylvania. They analyzed the words used by people on Facebook through their status updates and were able to count the number of times a specific word was used by a population of people. They then determined the percentage of times that specific word was used by those individuals.
Each word then became a frequency statistic. By linking specific words and connecting them to specific personal statistics such as age, gender and geography, correlations were then made. They were able to tease out words that showed the strongest statistical correlation to the outcomes they were questioning.
Word clouds were created to help people visualize those correlations. The size of the word encoded the “strength” of the correlation. The color encoded the “frequency” or the number of times that a word was used. By observing the following “word cloud” one can see that the <3 (heart emoticon) is the single most predictive feature of being “female” on Facebook. It is highly predictive because it’s both large (high correlation) and red (used frequently).
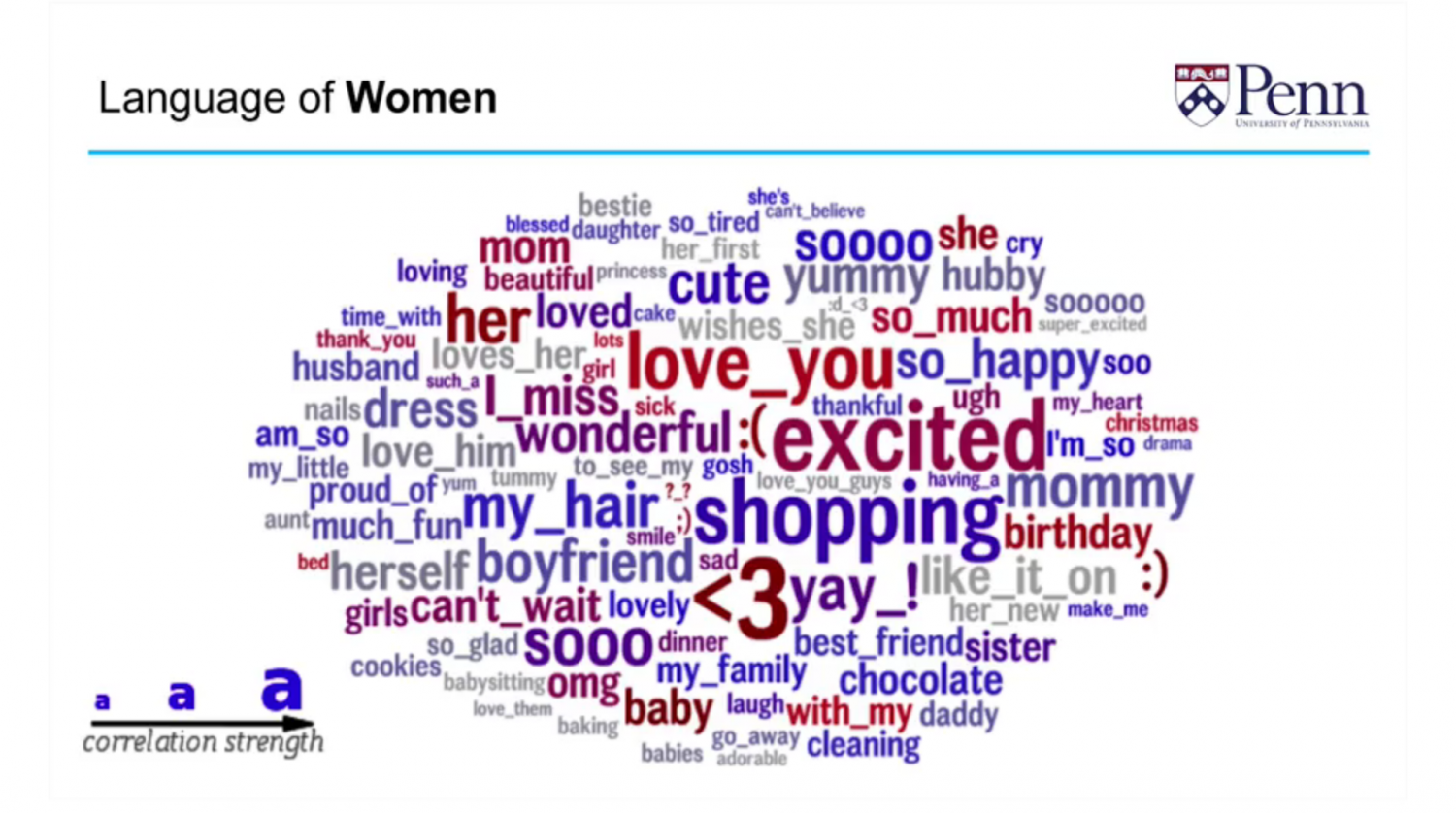
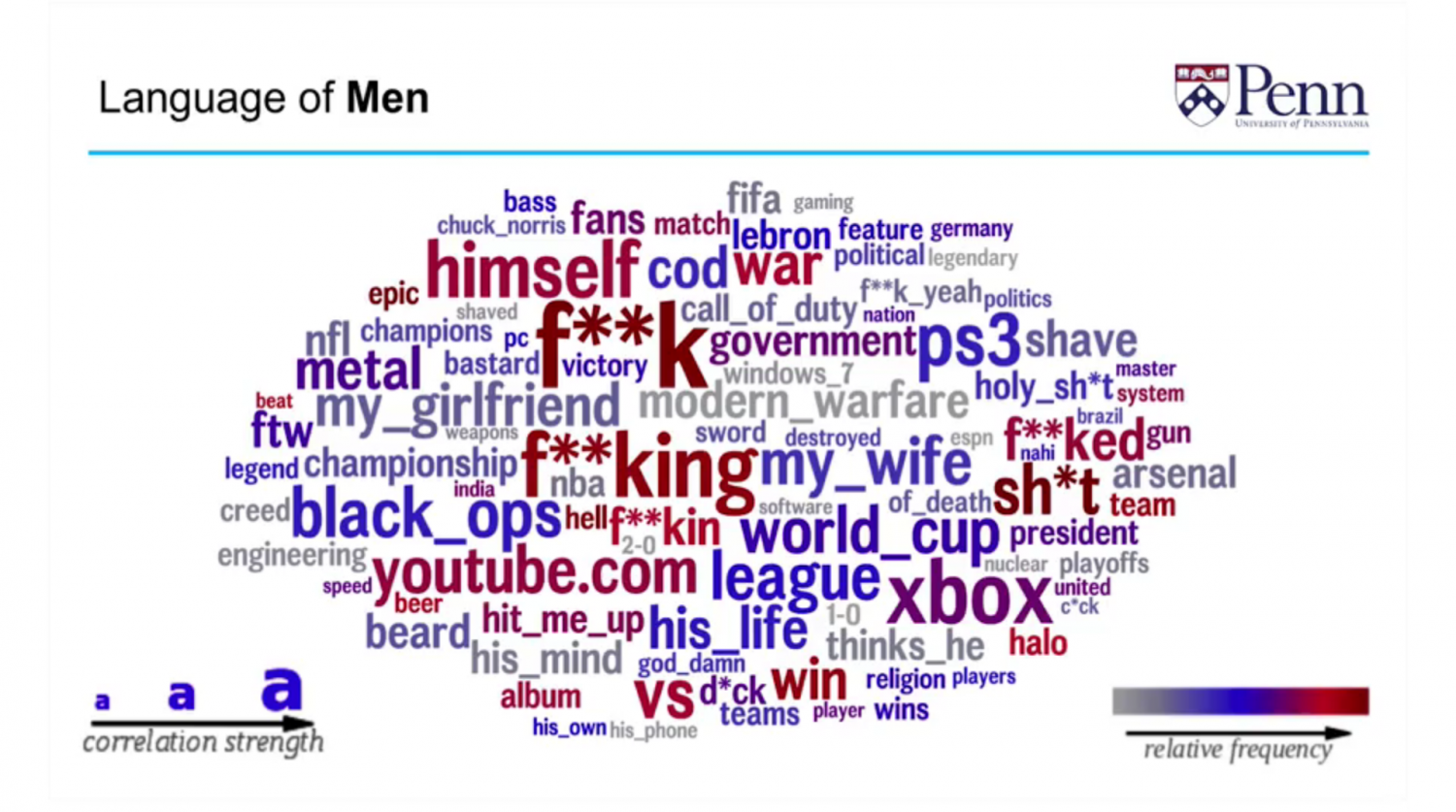
Compare this to the language of men. The first thing that jumps out at you is the curse words which show signs of “disagreeableness” and the tendency to break away from social norms. It is also easy to see correlations to competition with words such as video games and sports. Also, words like “beard” and “shaving” are more indicative of being male than female.
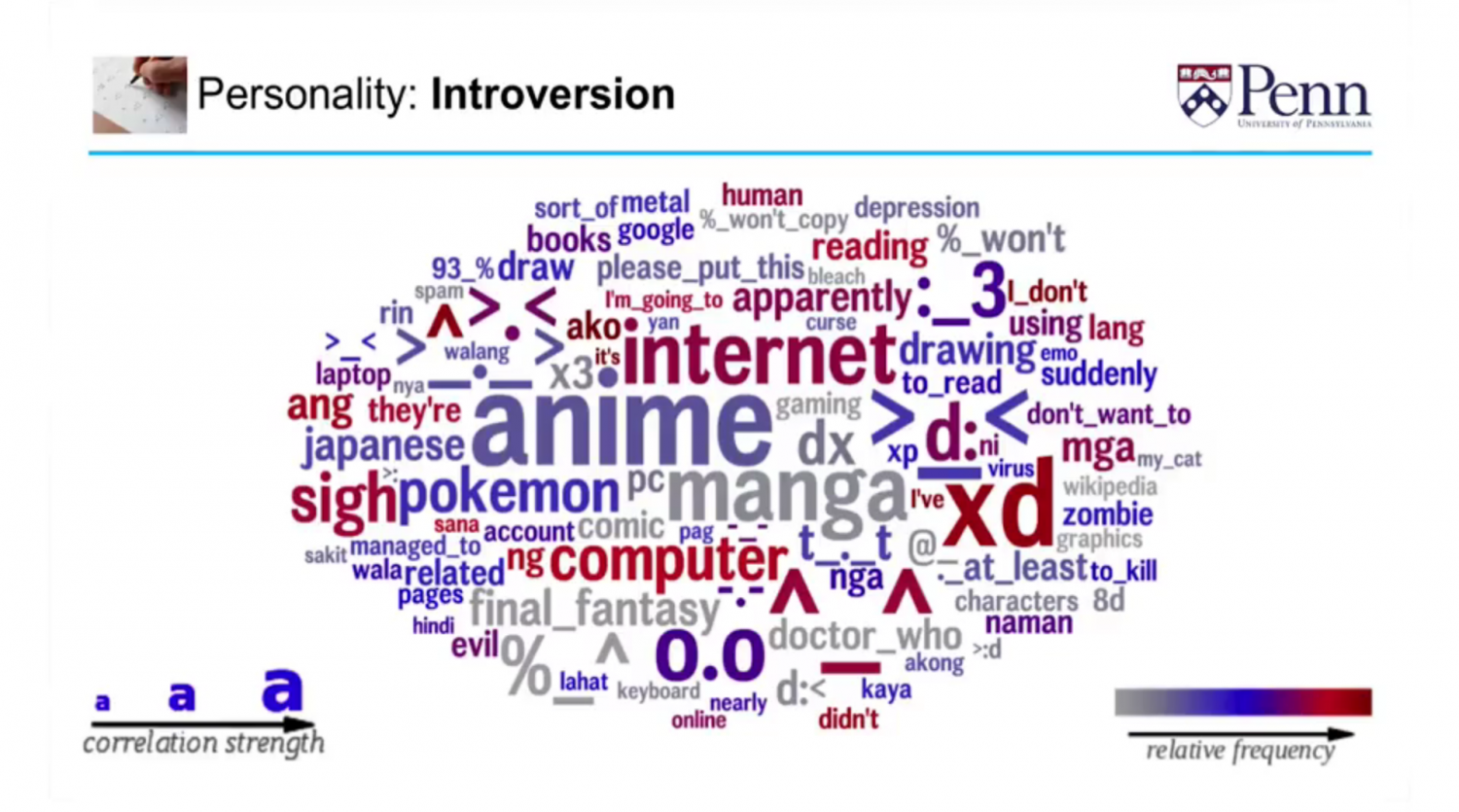
Below is the word cloud for extraversion. The single most predictive feature of being an extrovert is the word “party”. Extroverts also have a tendency to use a lot of “bigrams” or phrases with two words. Missing apostrophes is also indicative of extroversion because they usually show a lack of impulse control and the need for immediate attention and reward-seeking in social situations.

Introverts, on the other hand, commonly use words like “Pokemon”. Words associated with seclusion and the use of technology are also good indicators of introversion.
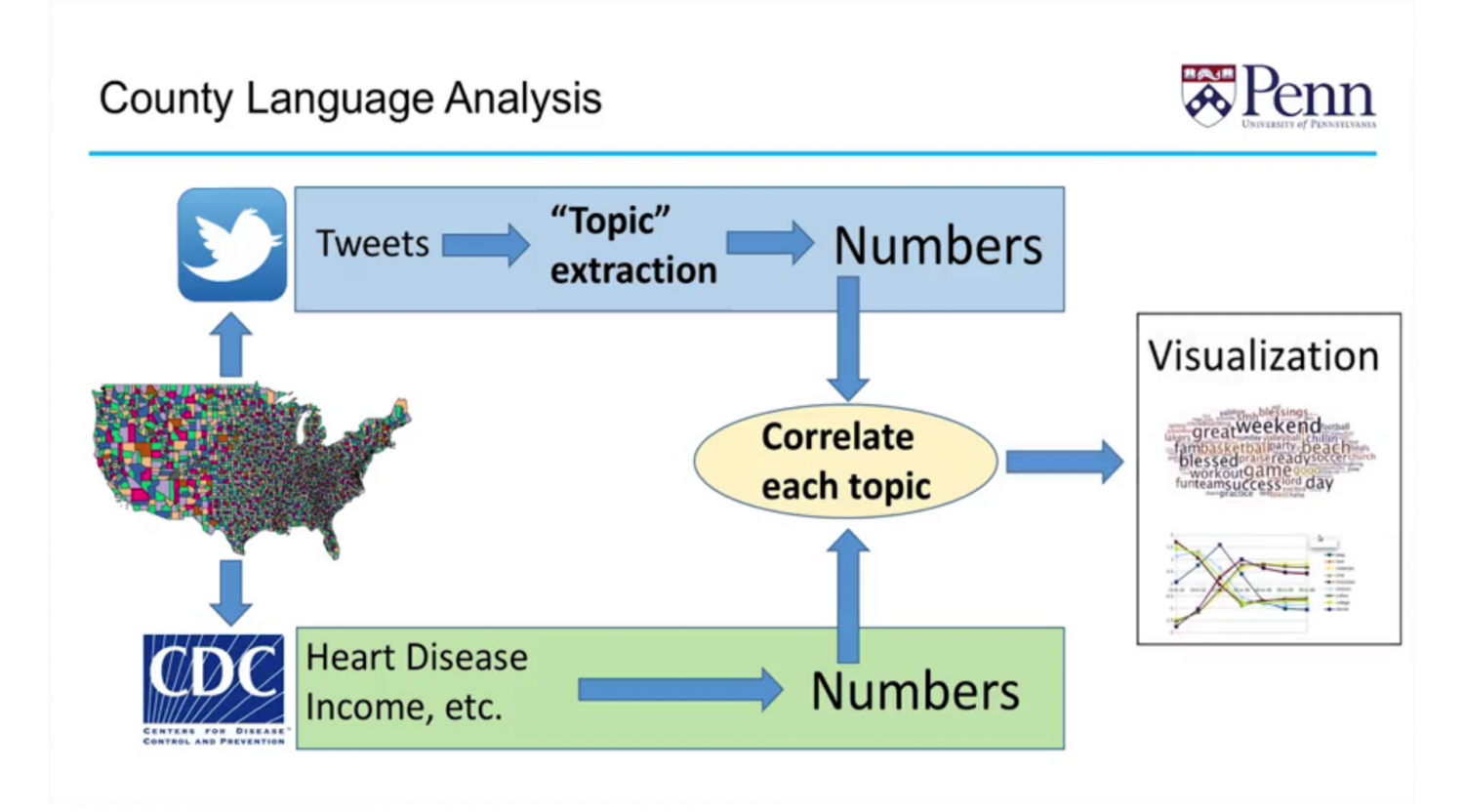
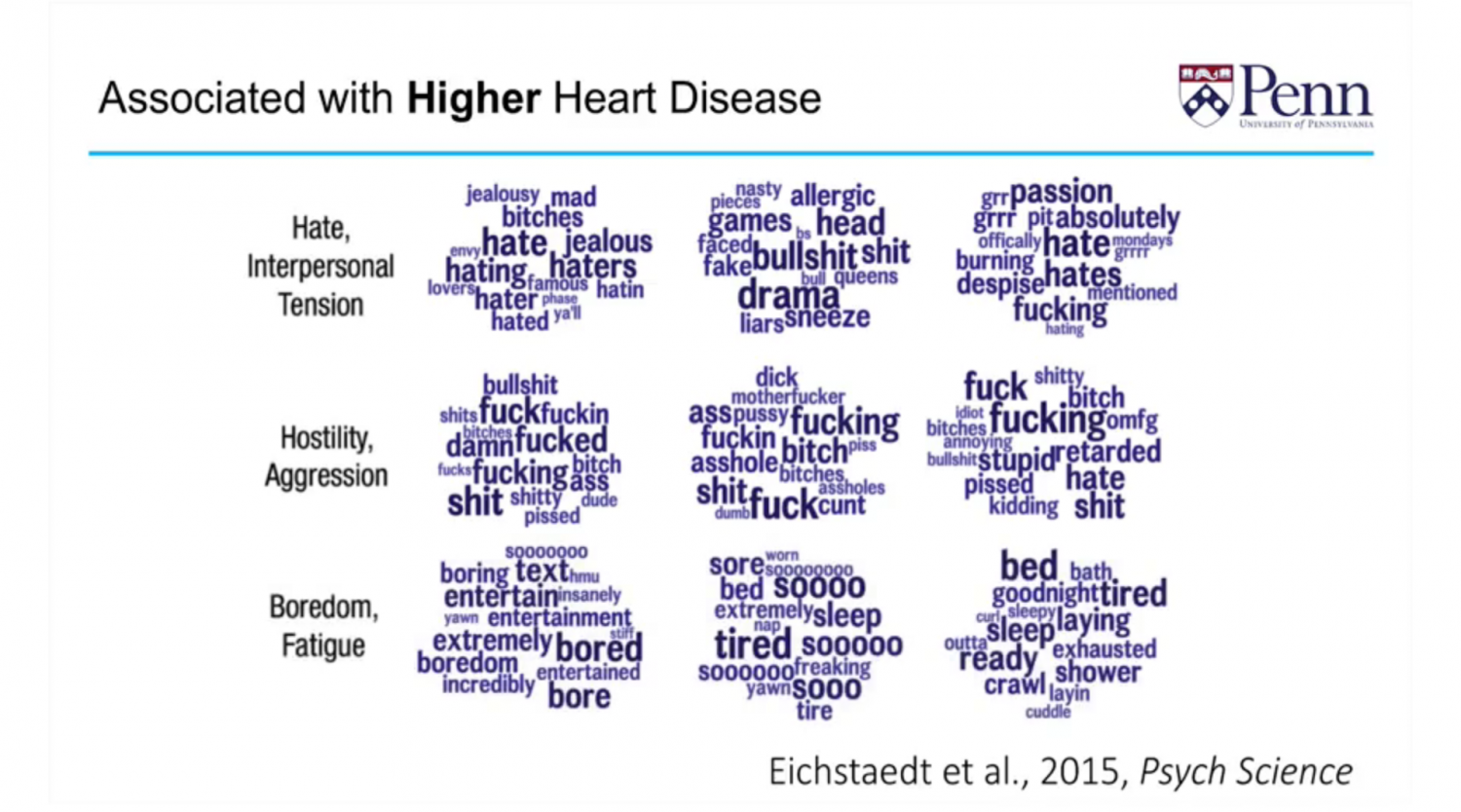
These researchers also analyzed a billion tweets and correlated them with their country of origin. They retrieved heart disease data from the Centers for Disease Control in the US, correlated the data with the Twitter words they had collected, and then created a word cloud that represented individuals who had heart disease. Words like hate, hostility, aggression, cursing, disagreeableness, boredom and fatigue were used most often.
 What’s interesting about all of this research is that the words or online “meta-tags” that we use in our day to day language can be very telling of who we are and the behaviors we will enact. Just like all big data analytics, the power lies in the predictive nature of these tools and eventually the ability to create interventions to intercede and prevent certain beliefs, perceptions, behaviors, and conditions.
What’s interesting about all of this research is that the words or online “meta-tags” that we use in our day to day language can be very telling of who we are and the behaviors we will enact. Just like all big data analytics, the power lies in the predictive nature of these tools and eventually the ability to create interventions to intercede and prevent certain beliefs, perceptions, behaviors, and conditions.
The Promise of Big Data in Pharma
A comprehensive analysis of the data points that can emerge from clinical studies, retailers, patients and caregivers can help manufacturers identify potential new drug candidates and develop them into effective, approved, and reimbursed medicines more efficiently. The race is on to create predictive models of biological processes and drugs without necessarily using patients. Patients can also be more readily identified and vetted for clinical trial inclusion using social media with much less expense and time. Clinical trials can be monitored in real time and safety or operational signals can be accelerated. Rigid data silos can be broken down and global data partnerships between manufacturers, academic researchers, CROs, providers, and payers can expedite innovation in a much more robust and time efficient manner.
Also, as outlined in the University of Pennsylvania example above, patient, practitioner and caregiver sentiments can be analyzed and mined to further understand the psychology of stakeholders with specific conditions and diseases. With that said, controls need to be created and diligently enforced to ensure patient privacy and security are maintained at the highest levels.
Digital forums, such as the Impetus InSite Platform, are great tools to facilitate IT-enabled portfolio decision-making. With asynchronous discussion forums such as InSite Exchange™, collaborators can voice opinions on issues and challenges and can log in on any device and at any time that is convenient for them over a 2-3 time period. In addition, researchers can co-develop clinical trial protocols or incorporate modifications using asynchronous annotation tools through these types of platforms. These systems can also help to reduce the administrative burden of managing virtual working groups by automating project elements such as customized email reminders and the collation of responses into transcript reports.
Collaboration platforms, which will be used to share and synthesize “big data” in the health arena, will enable manufacturers to respond to real-world outcomes and claims data. This will allow them to be better prepared to meet the demands of value-based pricing. Big data analytics promises to greatly improve drug safety, risk management, clinical trial efficiency, and patient adherence. The time is now for manufacturers to incorporate a data-centric approach by moving away from legacy technologies and disconnected data silos and to start investing in newer data sharing and collaboration technologies.
References
Alvarez, R. M. (2016). Computational social science: Discovery and prediction. Cambridge, UK: Cambridge University Press. http://dx.doi.org/10.1017/CBO9781316257340
Beaton, D., Dunlop, J., & Abdi, H. (2016). Partial least squares correspondence analysis: A framework to simultaneously analyze behavioral and genetic data. Psychological Methods, 21, 621–651.
Brandmaier, A. M., Prindle, J. J., McArdle, J. J., & Lindenberger, U. (2016). Theory-guided exploration with structural equation model forests. Psychological Methods, 21, 566–582.
Chapman, B. P., Weiss, A., & Duberstein, P. (2016). Statistical learning theory for high dimensional prediction: Application to criterion-keyed scale development. Psychological Methods, 21, 603–620.
Chen, E. E., & Wojcik, S. P. (2016). A practical guide to big data research in psychology. Psychological Methods, 21, 458–474.
Cheung, M. W. L., & Jak, S. (2016). Analyzing Big Data in Psychology: A Split/ Analyze/ Meta-Analyze Approach. Frontiers in Psychology, V7: 738. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4876837/
Friedman, J., Hastie, T., Simon, N., & Tibshirani, R. (2016). glmnet: Lasso and elastic-net regularized generalized linear models. R package 2.0–6. Retrieved from https://cran.r-project.org/web/packages/glmnet/glmnet.pdf
Gentry, J. (2016). Package “twitteR,” version 1.1.9. Retrieved from https://cran.r-project.org/web/packages/twitteR/twitteR.pdf
Jones, N. M., Wojcik, S. P., Sweeting, J., & Silver, R. C. (2016). Tweeting negative emotion: An investigation of Twitter data in the aftermath of violence on college campuses. Psychological Methods, 21, 526–541.
Kern, M. L., Park, G., Eichstaedt, J. C., Schwartz, H. A., Sap, M., Smith, L. K., & Ungar, L. H. (2016). Gaining insights from social media language: Methodologies and challenges. Psychological Methods, 21, 507–525.
Kosinski, M., Wang, Y., Lakkaraju, H., & Leskovec, J. (2016). Mining big data to extract patterns and predict real-life outcomes. Psychological Methods, 21, 493–506.
Landers, R. N., Brusso, R. C., Cavanaugh, K. J., & Collmus, A. B. (2016).
A primer on theory-driven web scraping: Automatic extraction of big data from the Internet for use in psychological research. Psychological Methods, 21, 475–492.
Miller, P. J., Lubke, G. H., McArtor, D. B., & Bergeman, C. S. (2016). Finding structure in data using multivariate tree boosting. Psychological Methods, 21, 583–602.
Stanley, C., & Byrne, M. D. (2016). Comparing vector-based and Bayesian memory models using large-scale datasets: User-generated hashtag and tag prediction on Twitter and Stack Overflow. Psychological Methods, 21, 542–565.